For baseline language models, I used 2-gram LMs trained on 222M words of newswire text using a variant of my CSR LM-1 training recipe. I used interpolated modified Kneser-Ney smoothing, with a count cutoff of 1 and no unknown word.
I used LMs with verbalized punctuation (VP) and a vocabulary of the top words in the CSR corpus. I eventually want to recognize short email/SMS-like messages that may contain multiple sentences. So I segmented the CSR training text into blocks of 1-6 contiguous sentences. Here are the LMs including the Sphinx binary DMP files and dictionaries:
5K CSR 2-gram with VP blocks
10K CSR 2-gram with VP blocks
20K CSR 2-gram with VP blocks
30K CSR 2-gram with VP blocks
40K CSR 2-gram with VP blocks
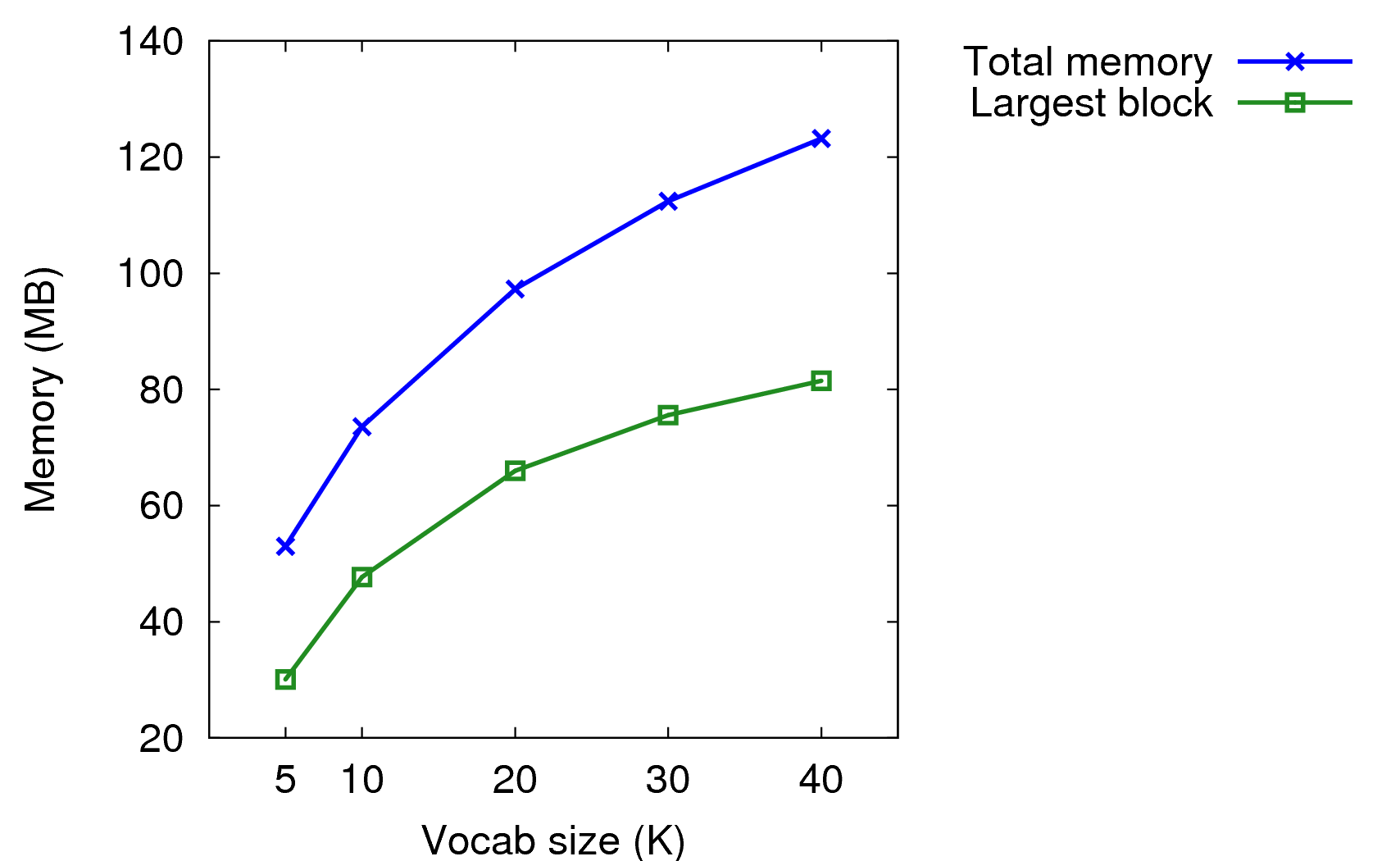
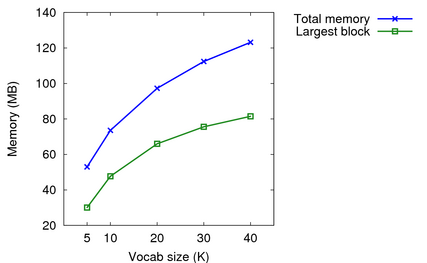
One important decision was how big a vocabulary to use as the N800 only has 128MB of flash memory. I ran an experiment to see the memory requirements of 5K, 10K, 20K, 30K and 40K language models. While there was memory overhead from the acoustic model, PocketSphinx, and my own software, the size of the language model still dominated. The memory size is as reported by pmap, before recognition of the first utterance. I've also listed the biggest block which is maybe the language model.
| Vocab size |
Total memory |
Largest Memory Block |
| 5k | 53.0 MB | 30.1 MB |
| 10k | 73.6 MB | 47.7 MB |
| 20k | 97.3 MB | 66.0 MB |
| 30k | 112.4 MB | 75.6 MB |
| 40k | 123.2 MB | 81.5 MB |
| Speaker-independent Recognition Tests |
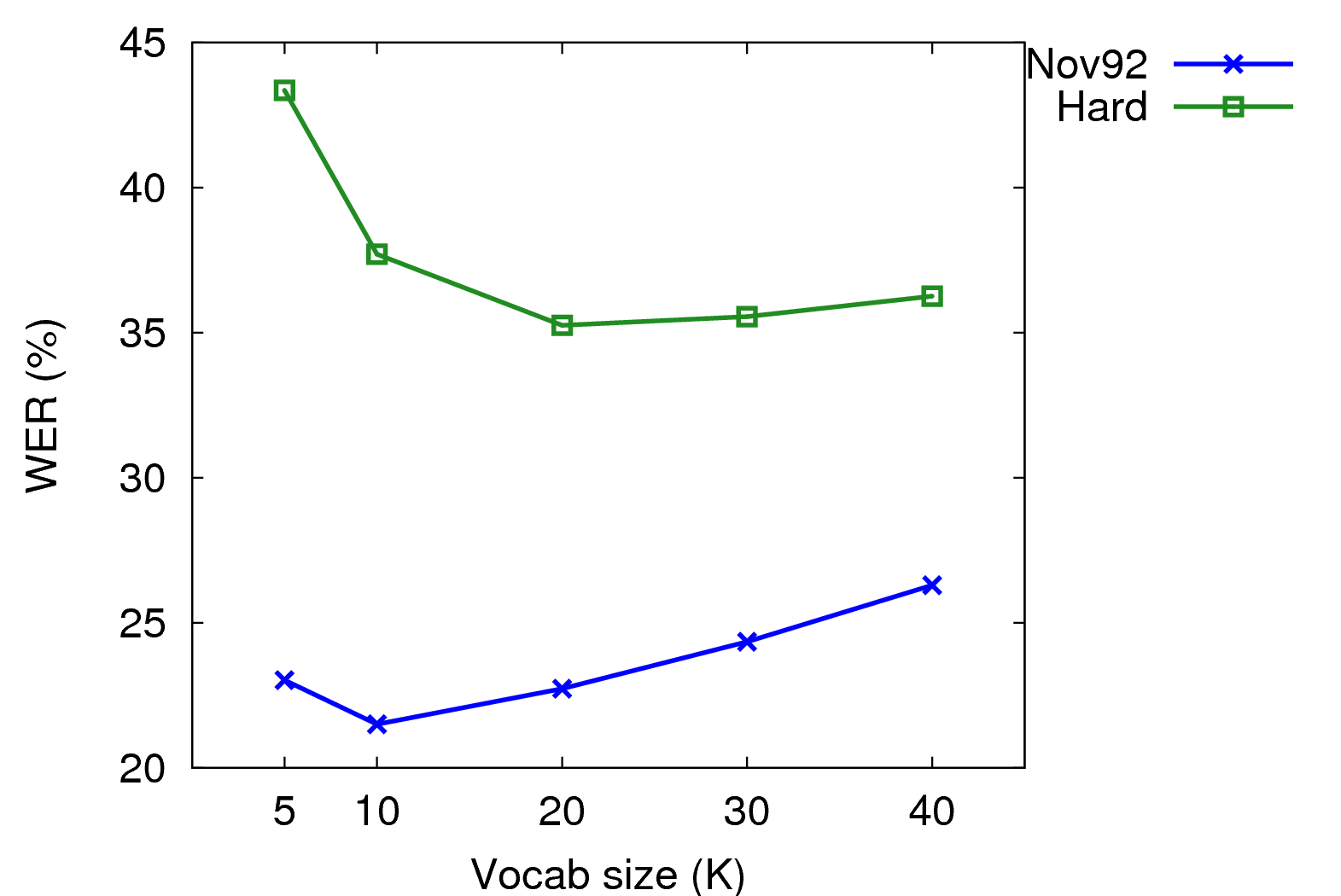
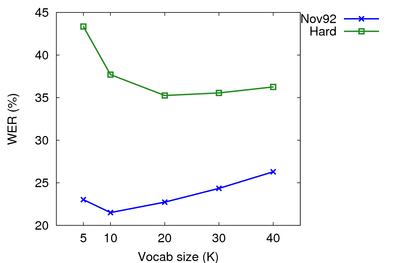
I ran recognition experiments using the speaker-independent narrowband acoustic model and these LMs. I used two WSJ test sets: Nov'92 (si_et_05, 330 utts) and Hard (wsj0 si_dt_jr, wsj1 si_dt_s2/sjm si_et_s2/sjm si_et_h1/wsj64k, 784 utts). Results were on the N800 and used the tuned parameters below.
Sphinx config file for 20K test
| Vocab size |
Nov'92 OOV |
Nov'92 WER |
Nov'92 xRT |
Hard OOV |
Hard WER |
Hard xRT |
| 5k | 2.90% | 23.03% | 0.988 | 12.55% | 43.36% | 1.143 |
| 10k | 0.95% | 21.51% | 0.966 | 7.24% | 37.71% | 1.153 |
| 20k | 0.41% | 22.73% | 1.048 | 3.91% | 35.26% | 1.212 |
| 30k | 0.28% | 24.35% | 1.084 | 2.38% | 35.56% | 1.274 |
| 40k | 0.13% | 26.30% | 1.183 | 1.69% | 36.26% | 1.304 |
There WERs aren't great, but accuracy had to be traded to obtain real-time performance and a reasonable memory footprint. Also there is a mismatch between my VP blocked LMs and the NVP single sentence utterances in the test sets. For further experiments, I used a vocabulary size of 20K. 20K provided a low out-of-vocabulary (OOV) rate and a reasonable memory footprint.
|